CVPR 2026 · Findings
ReFoCUS
Reinforcement-guided Frame Optimization for Contextual Understanding
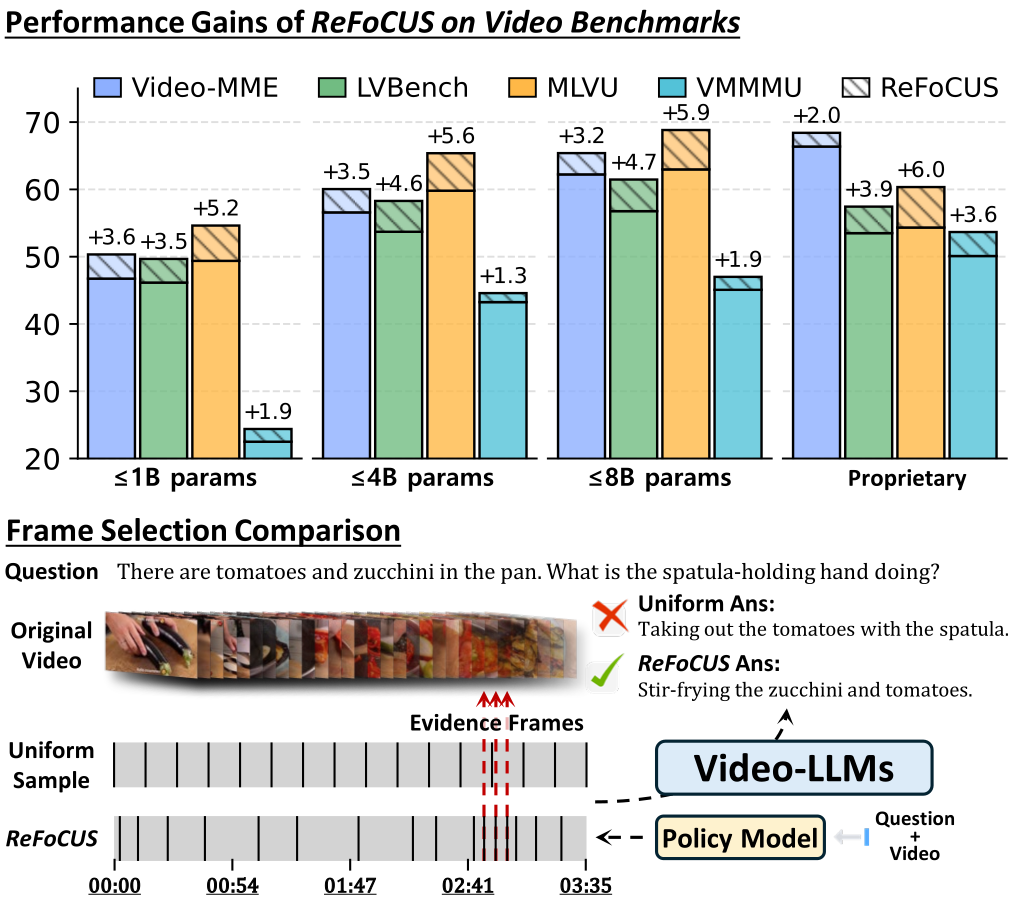
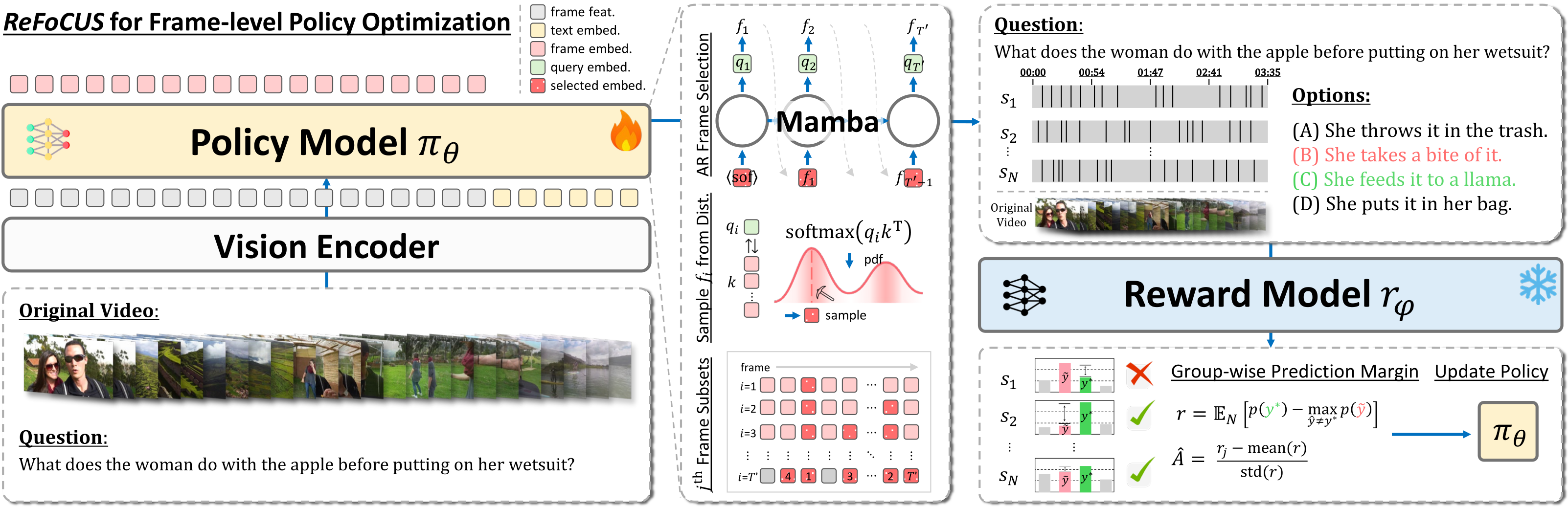
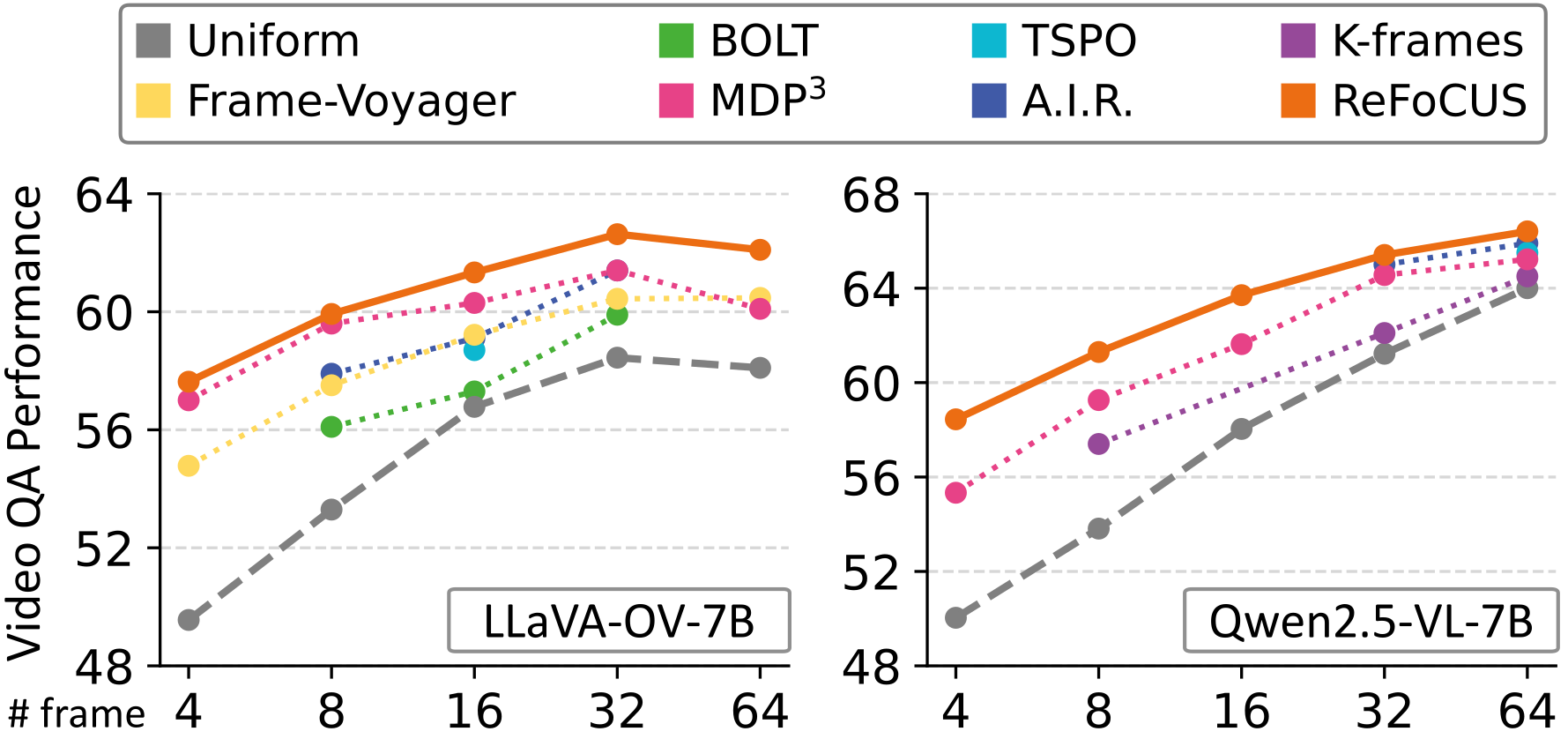
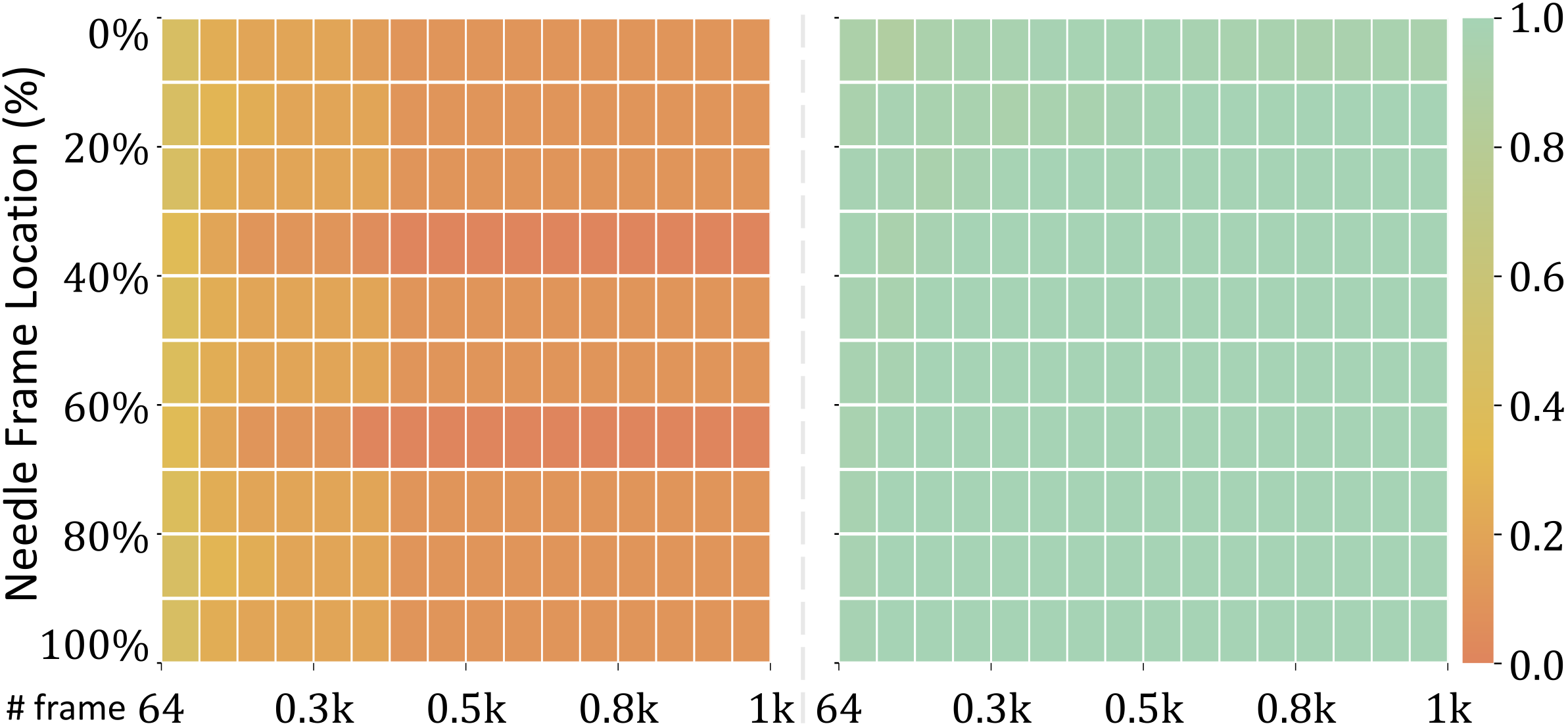
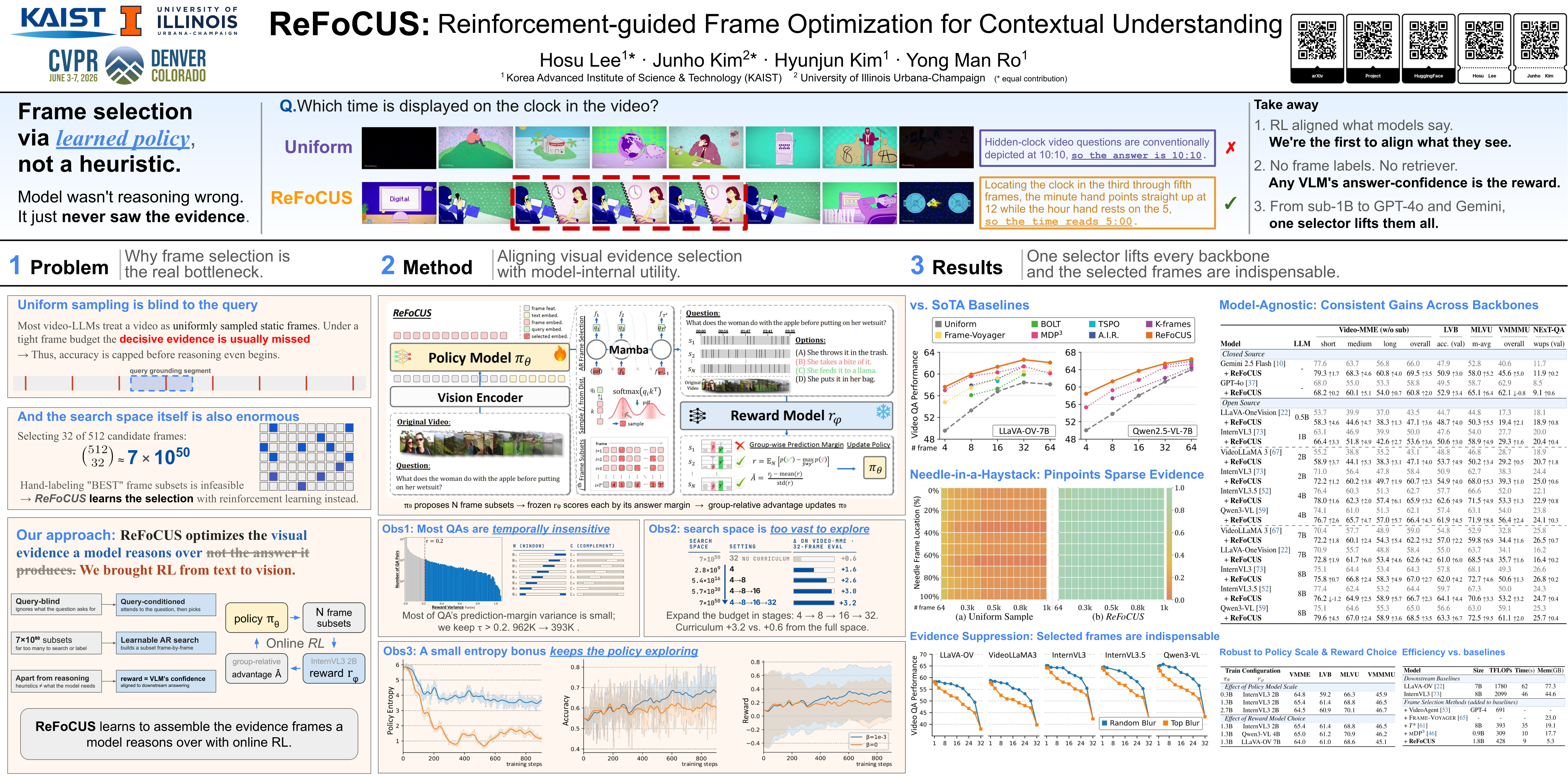
“Frame selection via a learned policy — not a heuristic. The model wasn’t reasoning wrong. It just never saw the evidence.”
1 KAIST · 2 UIUC · ∗ Equal contribution · † Corresponding author